Start your day with intelligence. Get The OODA Daily Pulse.
Informing your decisions with actionable intelligence
Start your day with intelligence. Get The OODA Daily Pulse.
Informing your decisions with actionable intelligence
It has become conventional wisdom that biotech and healthcare are the pace cars in implementing AI use cases with innovative business models and value-creation mechanisms. Other industry sectors should keep a close eye on the critical milestones and pitfalls of the biotech/healthcare space – with an eye toward what platform, product, service innovations, and architectures may have a potable value proposition within your industry. The Stanford Institute for Human-Centered AI (HAI) is doing great work fielding research in medicine and healthcare environments with quantifiable results that offer a window into AI as a general applied technology during this vast but shallow early implementation phase across all industry sectors of “AI for the enterprise.” Details here.
“Doctors worked with a prototype AI assistant and adapted their diagnoses based on AI’s input…this study shows that doctors who work with AI do so collaboratively. It’s not at all adversarial.”
While many healthcare practitioners believe generative language models like ChatGPT will one day be commonplace in medical evaluations, it’s unclear how these tools will fit into the clinical environment. A new study points to a future where human physicians and generative AI collaborate to improve patient outcomes. In a mock medical environment with role-playing patients reporting chest pains, doctors accepted the advice of a prototype ChatGPT-like medical agent. They even willingly adapted their diagnoses based on the AI’s advice. The upshot was better outcomes for the patients.
In the trial:
The study found that the doctors were not just receptive to AI advice but willing to reconsider their analyses based on that advice…the study’s findings go against the conventional wisdom that doctors may be resistant, or even antagonistic, to introducing AI in their workflows. “This study shows that doctors who work with AI do so collaboratively. It’s not at all adversarial,” said Ethan Goh, a healthcare AI researcher at Stanford’s Clinical Excellence Research Center (CERC) and the study’s first author. “When the AI tool is good, the collaboration produces better outcomes.”
The study was published in preprint by medRxiv and has been formally accepted by a peer-reviewed conference, AMIA Informatics Summit in Boston this March.
Milestone Moment
“It’s no longer a question of whether LLMs will replace doctors in the clinic — they won’t — but how humans and machines will work together…”
Goh quickly points out that the AI tools used in the study are only prototypes and are not yet ready or approved for clinical application. However, he said the results, as are the prospects for future collaborations between doctors and AI, are encouraging. “The overall point is when we do have those tools, someday, they could prove useful in augmenting the doctors and improving outcomes. And, far from resisting such tools, physicians seem willing, even welcoming, of such advances,” Goh said. In a survey following the trial, most doctors confirmed that they fully anticipate large language model-based (LLM) tools to play a significant role in clinical decision-making.
As such, the authors write that this particular study is “a critical milestone” in the progress of LLMs in medicine. With this study, medicine moves beyond evaluating whether generative LLMs belong in the clinical environment to how they will fit in that environment and support human physicians in their work, not replace them, Goh said. “It’s no longer a question of whether LLMs will replace doctors in the clinic — they won’t — but how humans and machines will work together to make medicine better for everyone,” Goh said.
“…much of the future of GenAI in medicine—and its regulation—hinges on the ability to substantiate claims; A new study finds that large language models used widely for medical assessments cannot back up claims.”
Large language models (LLMs) are infiltrating the medical field. One in 10 doctors already use ChatGPT daily, and patients have taken to ChatGPT to diagnose themselves. The Today Show featured the story of a 4-year-old boy, Alex, whose chronic illness was diagnosed by ChatGPT after over a dozen doctors failed to do so. This rapid adoption to much fanfare is despite substantial uncertainties about the safety, effectiveness, and risk of generative AI (GenAI). U.S. Food and Drug Administration Commissioner Robert Califf has publicly stated that the agency is “struggling” to regulate GenAI.
The reason is that GenAI sits in a gray area between two existing forms of technology:
However, because LLMs combine existing medical information with potential ideas beyond it, the critical question is whether such models produce accurate references to substantiate their responses. Such references enable doctors and patients to verify a GenAI assessment and guard against the highly prevalent rate of “hallucinations.” For every 4-year-old Alex, where the creativity of an LLM may produce a diagnosis that physicians missed, many more patients may be led astray by hallucinations. In other words, much of the future of GenAI in medicine—and its regulation—hinges on the ability to substantiate claims.
Evaluating References in LLMs
Unfortunately, very little evidence exists about LLMs’ ability to substantiate claims. In a new preprint study, we develop an approach to verify how well LLMs can cite medical references and whether these references support the claims generated by the models. The short answer: poorly. For the most advanced model (GPT-4 with retrieval augmented generation), 30% of individual statements are unsupported, and nearly half of its responses are not fully supported.
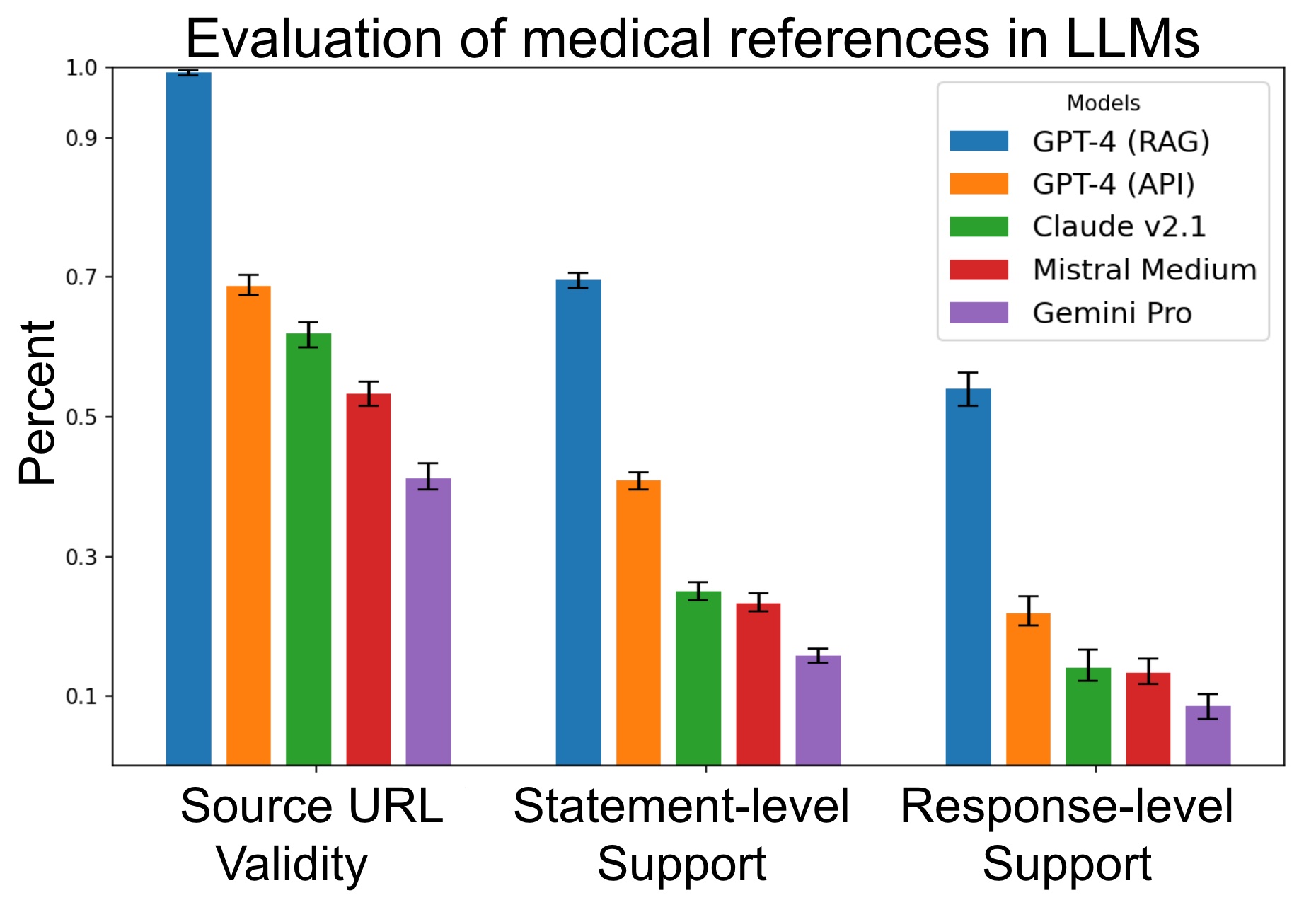
Evaluation of the quality of source verification in medical queries in LLMs. Each model is evaluated on three metrics over X questions. Source URL validity measures the proportion of generated URLs that return a valid webpage. Statement-level support measures the percentage of statements supported by at least one source in the same response. Response-level support measures the percentage of responses that have all their statements supported.
‘A Long Way to Go’
“As LLMs grow in their capabilities and usage, regulators and doctors should consider how these models are evaluated, used, and integrated.”
Many commentators have declared the end of health care as we know it, given the apparent ability of LLMs to pass U.S. Medical Licensing Exams. However, healthcare practice involves more than answering a multiple-choice test. It involves substantiating, explaining, and assessing claims with reliable scientific sources. And on that score, GenAI still has a long way to go.
Promising research directions include more domain-informed work, such as adapting RAG to medical applications. Source verification should be regularly evaluated to ensure that models provide credible and reliable information. At least by the current approach of the FDA – which distinguishes medical knowledge bases and diagnostic tools regulated as medical devices – widely used LLMs pose a problem. Many of their responses cannot be consistently and fully supported by existing medical sources. As LLMs grow in their capabilities and usage, regulators and doctors should consider how these models are evaluated, used, and integrated.
Consider the following when attempting to apply the lessons learned from these two studies in the healthcare sector by HAI researchers to your organization or industry:
Technology Convergence and Market Disruption: Rapid technological advancements are changing market dynamics and user expectations. See Disruptive and Exponential Technologies.
The New Tech Trinity: Artificial Intelligence, BioTech, Quantum Tech: Will make monumental shifts in the world. This new Tech Trinity will redefine our economy, threaten and fortify our national security, and revolutionize our intelligence community. None of us are ready for this. This convergence requires a deepened commitment to foresight preparation and planning on a level that is not occurring anywhere. The New Tech Trinity.
Benefits of Automation and New Technology: Automation, AI, robotics, and Robotic Process Automation are improving business efficiency. New sensors, especially quantum ones, are revolutionizing the healthcare and national security sectors. Advanced WiFi, cellular, and space-based communication technologies enhance distributed work capabilities. See: Advanced Automation and New Technologies
Rise of the Metaverse: The immersive digital universe is expected to reshape internet interactions, education, social networking, and entertainment. See Future of the Metaverse.

About the Author
Daniel Pereira is research director at OODA. He is a foresight strategist, creative technologist, and an information communication technology (ICT) and digital media researcher with 20+ years of experience directing public/private partnerships and strategic innovation initiatives.
Informing your decisions with actionable intelligence
Informing your decisions with actionable intelligence