Start your day with intelligence. Get The OODA Daily Pulse.
Informing your decisions with actionable intelligence
Start your day with intelligence. Get The OODA Daily Pulse.
Informing your decisions with actionable intelligence
Of the research outlets we have discovered since the launch of OODALoop.com, the Center for Security and Emerging Technology (CSET), OpenAI, and the Stanford Internet Observatory are best-in-class sources on topics of vital interest. A new report – “Generative Language Models and Automated Influence Operations: Emerging Threats and Potential Mitigations” – is the result of a partnership between these three organizations “to explore how language models could be misused for influence operations in the future, and provide a framework for assessing potential mitigation strategies.
The collaboration included an October 2021 workshop bringing together 30 disinformation researchers, machine learning experts, and policy analysts and culminated in a co-authored report building on more than a year of research. Their report outlines the threats that language models pose to the information environment if used to augment disinformation campaigns and introduces a framework for analyzing mitigation strategies.” (1)
We have been following this research since its inception with great interest. We also want to applaud OpenAI for participating in this research over the course of the last year. The press and the AI marketplace have put the cart before the horse in the overly positivist, groupthink-ish, techno-utopian initial response to the positive potential of OpenAI’s recently released ChatGPT platform. It is encouraging to see that OpenAI’s management and researchers are more clear-eyed and have dedicated resources to understanding the potential implications and impact – for good and for ill – of their technology.
Included here is a summary of this unique research collaboration’s findings on forecasting the potential unintended consequences of large language models and neural language models, especially their use in disinformation campaigns—and how to reduce risk.
As generative language models improve, they open up new possibilities in fields as diverse as healthcare, law, education, and science. But, as with any new technology, it is worth considering how they can be misused. Against the backdrop of recurring online influence operations—covert or deceptive efforts to influence the opinions of a target audience—the paper asks:
How might language models change influence operations, and what steps can be taken to mitigate this threat?
Our work brought together different backgrounds and expertise—researchers with a grounding in the tactics, techniques, and procedures of online disinformation campaigns, as well as machine learning experts in the generative artificial intelligence field—to base our analysis on trends in both domains.
We believe that it is critical to analyze the threat of AI-enabled influence operations and outline steps that can be taken before language models are used for influence operations at scale. We hope our research will inform policymakers that are new to the AI or disinformation fields, and spur in-depth research into potential mitigation strategies for AI developers, policymakers, and disinformation researchers.
When researchers evaluate influence operations, they consider the actors, behaviors, and content. The widespread availability of technology powered by language models has the potential to impact all three facets:
Our bottom-line judgment is that language models will be useful for propagandists and will likely transform online influence operations. Even if the most advanced models are kept private or controlled through application programming interface (API) access, propagandists will likely gravitate towards open-source alternatives and nation-states may invest in the technology themselves.
Many factors impact whether, and the extent to which, language models will be used in influence operations. Our report dives into many of these considerations. For example:
While we expect to see the diffusion of the technology as well as improvements in the usability, reliability, and efficiency of language models, many questions about the future remain unanswered. Because these are critical possibilities that can change how language models may impact and influence operations, additional research to reduce uncertainty is highly valuable.
To chart a path forward, the report lays out key stages in the language model-to-influence operation pipeline. Each of these stages is a point for potential mitigations. To successfully wage an influence operation leveraging a language model, propagandists would require that:
Many possible mitigation strategies fall along these four steps, as shown below.
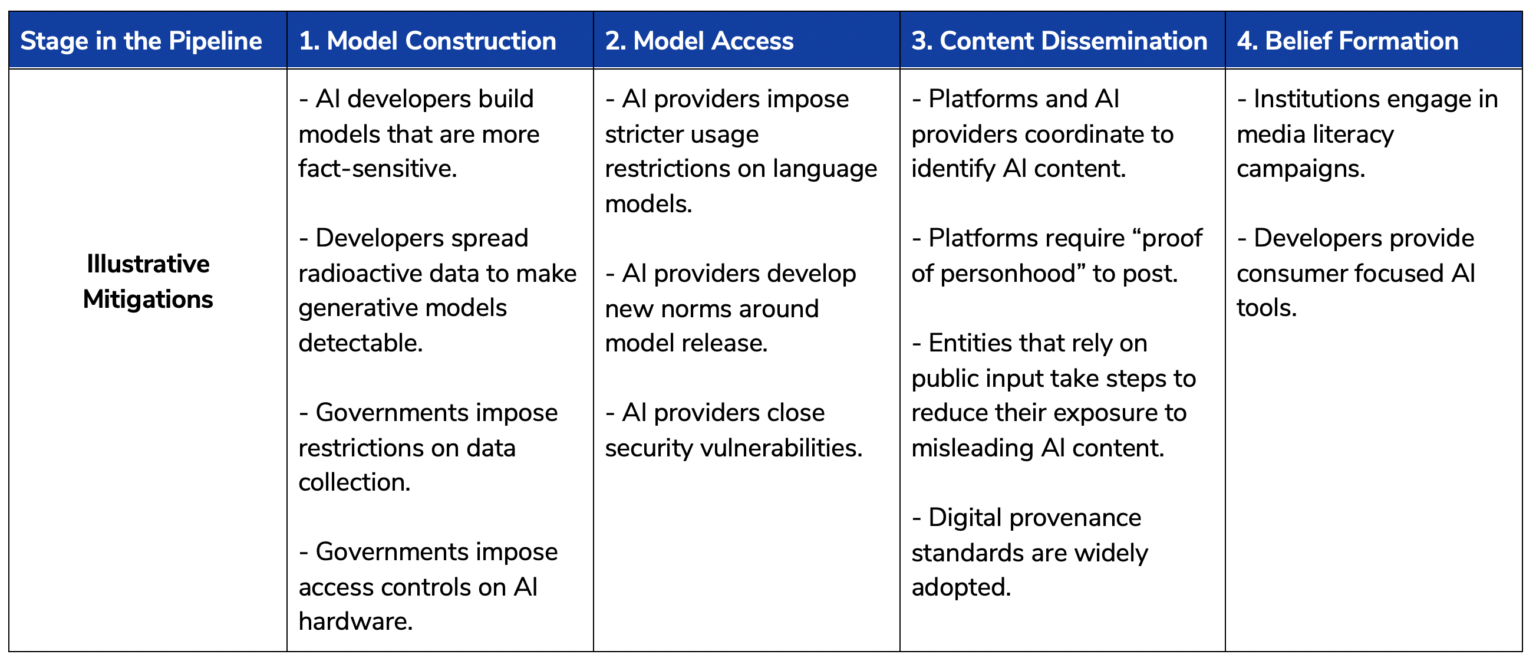
Just because a mitigation could reduce the threat of AI-enabled influence operations does not mean that it should be put into place. Some mitigations carry their own downside risks. Others may not be feasible. While we do not explicitly endorse or rate mitigations, the paper provides a set of guiding questions for policymakers and others to consider:
We hope this framework will spur ideas for other mitigation strategies, and that the guiding questions will help relevant institutions begin to consider whether various mitigations are worth pursuing.
This report is far from the final word on AI and the future of influence operations. Our aim is to define the present environment and to help set an agenda for future research. We encourage anyone interested in collaborating or discussing relevant projects to connect with us. For more, read the full report here.
https://oodaloop.com/archive/2021/12/09/cset-introduces-a-disinformation-kill-chain/
https://oodaloop.com/archive/2021/12/20/cset-releases-part-ii-of-series-ai-and-the-future-of-disinformation-campaigns/
https://oodaloop.com/archive/2021/08/19/ai-accidents-framework-from-the-georgetown-university-cset/
https://oodaloop.com/archive/2023/01/04/the-2022-ooda-loop-series-autonomous-everything/
For posts in the Autonomous Everything Series, click here.

About the Author
Daniel Pereira is research director at OODA. He is a foresight strategist, creative technologist, and an information communication technology (ICT) and digital media researcher with 20+ years of experience directing public/private partnerships and strategic innovation initiatives.
Informing your decisions with actionable intelligence
Informing your decisions with actionable intelligence