Start your day with intelligence. Get The OODA Daily Pulse.
Informing your decisions with actionable intelligence
Start your day with intelligence. Get The OODA Daily Pulse.
Informing your decisions with actionable intelligence
Large Language Models (LLMs) based on deep learning have been a part of the technological landscape since approximately 2018. However, their existence was initially unknown to the general public, with their usage largely confined to a few technical disciplines such as data scientists and software engineers. This all changed in late 2022 when ChatGPT, a Generative Pre-trained Transformer (GPT) from OpenAI, exploded onto the scene with more than 180 million users in its first year.

The following year, in 2023, several related capabilities emerged, including Google Bard, Anthropic Claude, and X Grok. These advancements, led by ChatGPT and related LLMs, created a massive shift in the way we interact with technology. They presented informal chat via text as a new, powerful user-interface (UI) for connecting users with AI capabilities. This revolution in UI has transformed the way we interact with AI, making it more accessible and user-friendly than ever before.
Is this just another passing fad like bitcoin, metaverse, or blockchain? In short, no. LLMs are postured to have a profound impact on knowledge work and how people interact with computers now and in the future.
There is way too much going on related to LLMs to cover everything in one article. In this article we’ll explore:
Simple examples of using LLMs
The number of LLMs available today are legion. If you count open-source LLMs, there are thousands of LLMs in existence. Five high-quality LLMs that I have experimented with recently include: OpenAI’s ChatGPT, Microsoft Bing Chat, Google Bard, Anthropic Claude, and HuggingFace Zephyr.
A Simple Question: Trivia
I asked each of these five models a simple question, that could easily be answered using Wikipedia. The question was “Please limit your answer to two sentences. Who is the queen of Spain?”
OpenAI ChatGPT example. As of my last update in April 2023, the Queen of Spain is Queen Letizia. She is married to King Felipe VI, who ascended to the throne in June 2014.
Microsoft Bing Chat example. The queen of Spain is Letizia Ortiz Rocasolano, who is the wife of King Felipe VI. She became queen consort in 2014, after her father-in-law, King Juan Carlos, abdicated the throne.
Google Bard example. The current queen of Spain is Letizia Ortiz Rocasolano, who has been queen consort since 2014. She is married to King Felipe VI.
Anthropic Claude example. The current queen of Spain is Letizia Ortiz. She became queen consort of Spain when her husband, King Felipe VI, ascended to the throne in 2014.
HuggingFace Zephyr example. As of my training data, which is current as of September 2021, the queen of Spain is Letizia, wife of King Felipe VI.
As you can see, all five provided essentially the same facts. Although not depicted here, Bing Chat and Google Bard both provided URLs to the source material that their answers were based on. Checking Wikipedia we can see that all five LLMs were correct. LLMs are awesome!
Findings
A More Challenging Example: Spatial Relationships
Okay so for basic facts LLM’s are pretty good. In fact, LLMs have encyclopedic knowledge that is greater than any individual human. Recent benchmark showed that many LLM are capable of passing standardized tests. OpenAI’s GPT-4 even passed the bar exam.
But what if we have a more difficult question? What if we are looking for information that is not inherently, textual in nature, but relates to time space or some other dimension? Are current LLM’s capable of reasoning about geospatial information? To find out, I asked the chat-bot interface of these LLMs a different type of question: “What are the three hospitals closest to 51.4949, 0.0092?” (This is the latitude and longitude of a sports field near the River Thames in Greenwich, London, England.)
Spoiler alert: some of these LLMs cheated and tried to use the ‘location services’ data available from my web-browser. If any of their recommendations were near where I live, I’d leave them out to protect my privacy. But none of the recommendations were close to where I live, so I kept them in.
Microsoft Bing Chat example. Here Bing Chat was way off. Its answer must have ignored my query and used my web-browser’s location services. In its answer it reported back: Reston Hospital Center in Reston Virginia, Inova Emergency Room in Reston Virginia, and Inova Keller Center in Fairfax Virginia. Not even close! It is thousands of miles away.

Google Bard example. Google made the same mistake. Instead of using the coordinates in my query, Google ignored them and responded with Reston Hospital Center in Reston Virginia, Stone Springs Hospital Center in Dulles Virginia, and Inova Loudon Hospital in Leesburg Virginia. Still thousands of miles away from the correct answer.

Anthropic Claude example. Refreshingly, Claude told me “Unfortunately I do not have enough context to provide specific information about hospitals near that location without knowing the city or region.” When I reframed the question as “What are the closest three hospitals to Greenwich, London, England?” it was able to recommend some suggestions that were within 10 miles of the coordinates in my original question. But they were still irrelevant, as there are many hospitals closer to my query coordinates.

HuggingFace Zephyr example. In this challenge, HuggingFace bested Bing Chat, Bard, and Claude. Given my original question with coordinates, it returned three hospitals all within approximately 3km of the location that I mentioned. Still not the closest three hospitals, but much better than the other chat bots so far. Open-source FTW (for the win)!

OpenAI ChatGPT example. I was pretty sure that ChatGPT would be totally stumped by this question. But in fact, it queried Bing Maps and came up with a good answer. I found this hilarious because Microsoft (creator of Bing Maps!) failed to use their own map data to come up with a correct answer. Of the three hospitals provided by ChatGPT one of them was pretty close, but the other two were not very close the coordinates I shared.
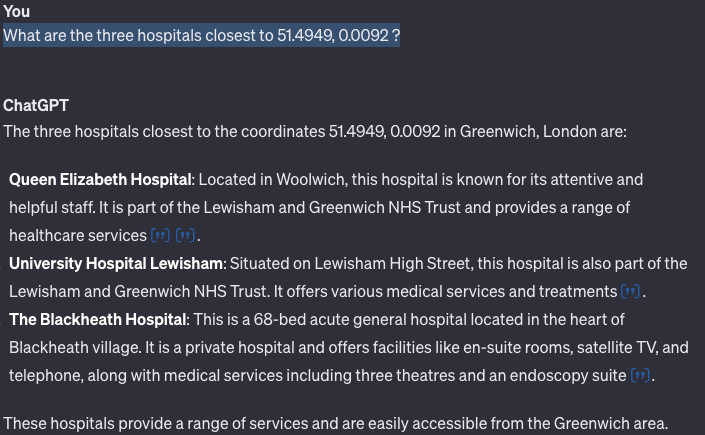
Findings
A shift from general LLMs to tailored LLMs
It’s great to have common LLMs like ChatGPT that allow us to discover general public information in a question-answer format. But this opens many questions related to private data. What if I want to use LLMs to ask questions about private data belonging to me or my organization? How can I incorporate private data into an LLM? Is it safe to put private data into a public LLM? How can I achieve similar capabilities, while still protecting the privacy and information security?
Option One: Fine-tuning
One option to this problem is making your own model updated model using a process called fine-tuning. LLM fine-tuning refers to the process of refining a Large Language Model (LLM) after its initial training. The initial training of an LLM involves learning from a large amount of text data. However, this model may not be perfect for specific tasks or domains. Therefore, it is “fine-tuned” on a smaller, specific dataset related to the task at hand. This fine-tuning process allows the model to adapt its previously learned knowledge to perform well on the specific task it is “tuned” for, improving its narrowly focused capabilities in a specific context or domain.
| Positives of fine-tuning | Negatives of fine-tuning |
| Improves performance of a model on a specific task | Technical expertise required for fine-tuning and testing the subsequent model |
| Much less resource intensive than training a machine learning model from scratch | Although resource requirements are reduced, it still may require more GPU compute than organizations have |
| Does not require as much data as training from scratch | Fails to address “new data” that arrives after the fine-tuning takes place |
In many cases, fine-tuning doesn’t make sense. In addition to the cost and complexity of fine-tuning, the constant influx of new data into organizations means that as soon as a model is created or fine-tuned it is out of date.
Option Two: Retrieval Augmented Generation (RAG)
A low-cost way of being able to tap into recent data while still using an LLM is through what is called retrieval augmented generation (RAG). RAG is a method that combines the power of language models with external knowledge sources to enhance the quality and relevance of the generated text.
Here’s a breakdown of how RAG works:
Retrieval: When a query or prompt is given to the system, the retrieval component searches a large corpus of documents (such as Wikipedia or a specialized database) to find relevant information. This is often done using a dense vector search where documents and queries are embedded into a high-dimensional space, and the nearest neighbors (most relevant documents) are retrieved based on vector similarity.
Augmentation: The retrieved documents are then provided to the language model as additional context. This helps the model to generate responses that are informed by the retrieved information, which can be particularly useful for answering factual questions or when specific details are required.
Generation: Finally, the language model generates a response or continuation of the text, considering both the original prompt and the information from the retrieved documents.
RAG models are particularly useful in scenarios where the language model alone might not have enough information to generate accurate or up-to-date responses. By accessing external sources, RAG can provide more precise and contextually relevant outputs.

One solution to the inconsistent results of geospatial analysis questions I covered earlier in this article is to create a RAG extension to LLMs that allows them to send information requests out to services outside of the LLM. For example, I built an AI assistant named Location-GPT that enables Chat-GPT to call out to a geospatial database of points of interest to answer questions about where certain points of interest are located in London.
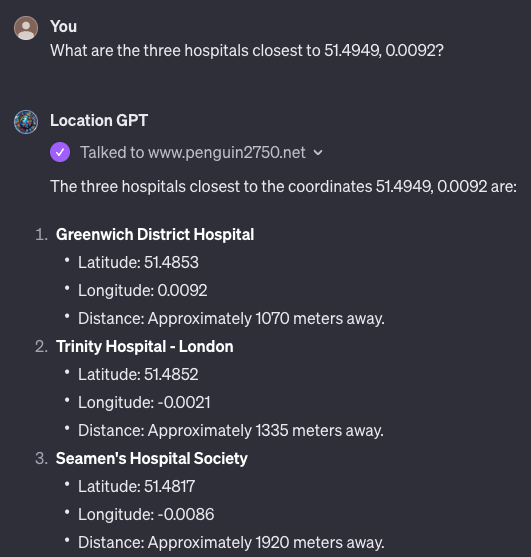
Using RAG to combine the LLM powering ChatGPT with an external system that has spatial analysis capabilities yields much better results for geospatial queries.
Findings
The emergence of ‘agents’
It’s very difficult to create a single LLM that knows everything about everything. Even with LLMs enhanced by fine-tuning or RAG, it is unwieldy to try to create a “one size fits all” system that knows everything and can do everything.
In modern economies, people specialize in different fields and work together in teams to accomplish things greater than they could individually. To extend the power of LLMs I have witnessed a similar trend of implementing and connecting intelligent “agents” that are each powered by specialized LLMs and connected to tools like RAG-systems and APIs. These connected networks of agents communicate and collaborate on solving multi-step problems that are too complex for any single system.
Three very impressive software libraries for programmatically creating teams of AI agents are Microsoft AutoGen, ChatDev, and OpenAI Assistants. On the AutoGen website, Microsoft provides more than twenty examples of how to spin up agent teams to solve technical challenges.
One example by Microsoft that really impressed me is a technical challenge to automate writing python code to check stock prices and make a line chart of year-to-date stock performance. To complete the challenge, you create a technical manager agent and a software engineering agent. Via a simple text description, you tell the technical manager agent what code you want written. Then the technical manager iteratively chats with the software engineering to build, test, and refine the python code. In a period of less than 60 seconds, the two agents create working code to solve this complex multi-step process.
Conclusion
As we reflect on the current state of Large Language Models (LLMs), it’s clear that they have become a transformative force in the technological landscape. Their ability to understand and generate human-like text has opened up new possibilities for human-computer interaction. From answering simple trivia questions with remarkable accuracy to attempting to navigate more complex spatial queries, LLMs have demonstrated both their strengths and limitations. While they can provide encyclopedic knowledge, their performance on tasks requiring real-time data or spatial reasoning can be inconsistent.
The transition from general to personal LLMs raises important considerations regarding privacy and data security. Retrieval-Augmented Generation (RAG) offers a promising approach, allowing LLMs to access up-to-date information without compromising user privacy. This balance between personalization and privacy will be crucial as LLMs become more embedded in our daily lives.
The emergence of ‘agents’—specialized LLMs equipped with domain-specific knowledge and connected to tools like RAG systems and APIs—suggests a future where AI collaboration mirrors that of human teamwork. These networks of intelligent agents have the potential to tackle multi-faceted problems by communicating and collaborating, much like teams of people in the modern economy. This could lead to significant efficiency gains and breakthroughs in complex problem-solving.
Looking ahead, we can expect LLMs to continue evolving, becoming more integrated with other technologies and more adept at handling a variety of tasks. As they do, it will be essential to consider the ethical implications of their use, including issues of bias, accountability, and the impact on employment.
I encourage readers to experiment with LLMs, identify the logical boundaries where they break down, and to consider how they can be safely applied in the future. Matt Devost provides an excellent blog post about his experience making a custom GPT. The future of work is poised for significant change as LLMs become more sophisticated and widespread.

About the Author
Abe Usher is an ex-Google engineer and serial entrepreneur. He is currently the Co-CEO of Black Cape, a technology startup that specializes in enterprise software engineering and innovative data analytics. Mr. Usher is an award-winning technology leader and data scientist. His innovative ideas have been featured in leading publications such as Wired Magazine, Business Week, Network World, CNET News, Trajectory Magazine, and the Geospatial Intelligence Forum. He has also presented talks at Harvard Business School, MIT, General Electric, the Nielsen Company, National Defense University, and more. Mr. Usher has served his country in both the U.S. Air Force as a cyber operations officer and in the U.S. Army as an Infantry Leader. He received his bachelor's degree from the U.S. Military Academy, West Point and his master's in Information Systems and Software Engineering from George Mason University.
Informing your decisions with actionable intelligence
Informing your decisions with actionable intelligence